lumberjack: 滚动日志源码走读
是什么
Lumberjack 是一个用于将日志写入滚动文件的 Go 包,旨在成为日志系统基础设施的一部分。它不是一个一体化的解决方案,而是日志记录堆栈底部的一个可插入组件,仅控制写入日志的文件。
解决了什么问题
- 无侵入式的日志切割
- 关注点分离:只关注日志的文件管理
Quick Start
1 | log.SetOutput(&lumberjack.Logger{ |
只需使用 *lumberjack.Looger 结构作为 io.WriteCloser 的实现替代例如 os.File 结构等,传入各类日志 logger 的配置中作为输出目标,即可将日志写入滚动文件
- 日志文件分割:日志文件大小超过限制,将日志归档并创建新日志文件
- 日志文件清理:旧日志数目超过限制,按时间对日志进行清理
- 日志文件压缩:旧日志压缩
源码分析
核心结构
lumberjack.Logger
唯一暴露在外的结构 Logger,作为io.WriteCloser 接口的实现
1 | type Logger struct { |
可导出的变量:
- Filename:输出日志的文件名,这个文件名是一个全路径,即日志文件会在Filename指定的文件的目录下,进行存储和老化
- MaxSize:日志文件的最大占用空间,也就是日志文件达到多大时触发日志文件的分割。单位是MB
- MaxAge:已经被分割存储的日志文件最大的留存时间,单位是天
- MaxBackups:已经被分割存储的日志文件最多的留存个数。MaxBackups 和上面的 MaxAge 会共同生效,满足二者中的一个条件就会触发日志文件的删除
- LocalTime:被分割的日志文件上的时间戳是否要使用本地时区,默认会使用UTC时间
- Compress:指定被分割之后的文件是否要压缩。使用 gzip 算法压缩
内部变量:
- size:当前日志文件大小
- file:当前日志文件
- mu:Logger 的全局锁
- millCh:用于唤醒 millRun,进行日志文件压缩删除的处理
主流程
流程图
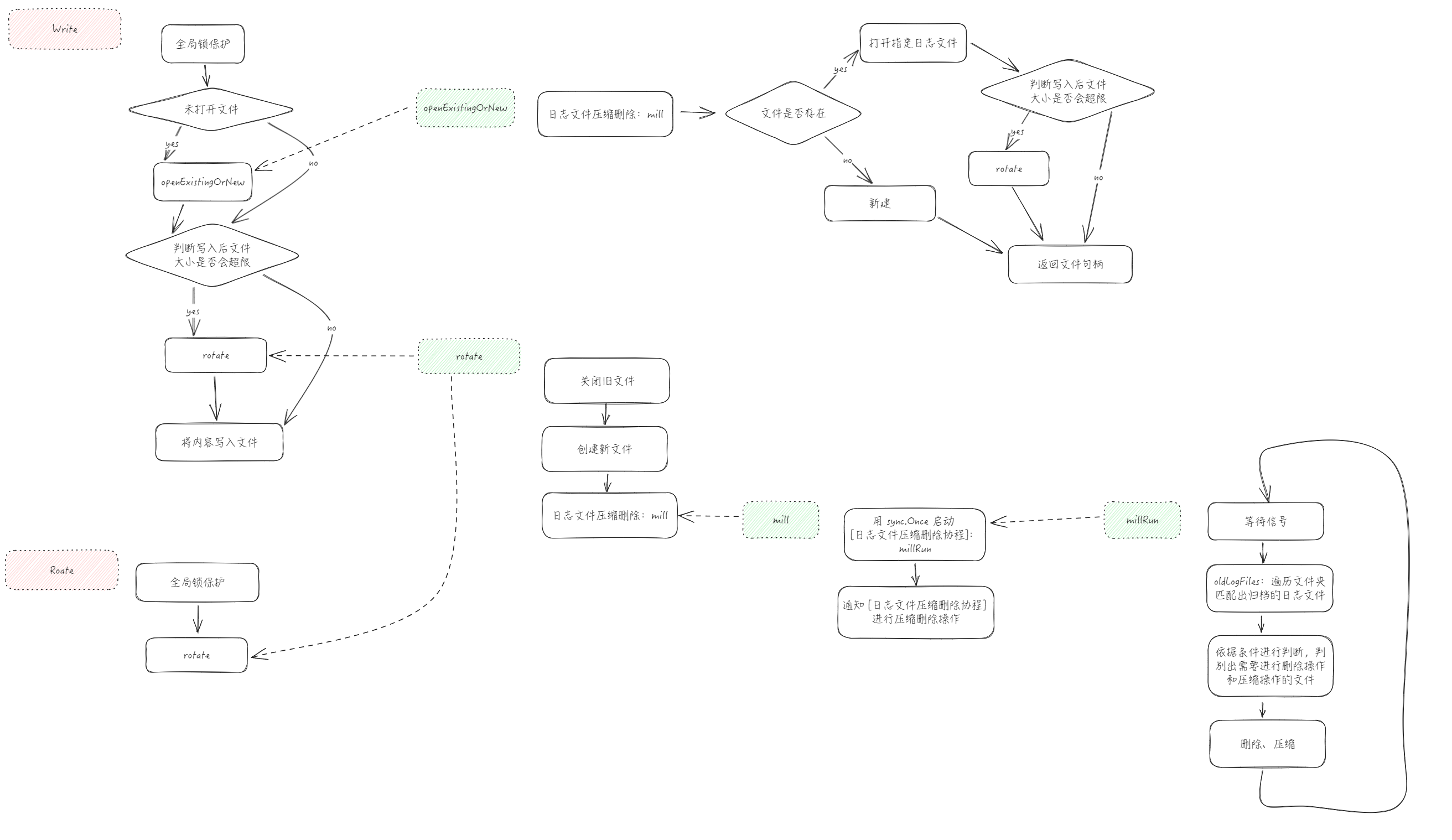
Write
1 | // Write implements io.Writer. If a write would cause the log file to be larger |
Write的逻辑很简单,先全局上锁保证并发安全,对入参做必要的校验,然后根据文件句柄的存在情况决定是否需要打开文件和创建文件、依据和日志文件写入后的大小判断是否要进行日志分割,最终调用写文件的方法,真正写入文件
下面分别看其中用到的 openExistingOrNew(负责获取到一个可写入的文件) 和 rotate(负责日志分割) 这两个关键方法
openExistingOrNew
1 | // openExistingOrNew opens the logfile if it exists and if the current write |
如果满足三个条件中的任何一个,就会创建新文件返回
- 文件不存在
- 文件大小加上本次要写入内容后会超过限制
- 文件打开失败
基本保证一定会获取到一个能写入日志信息的文件
这里调用了两个特别的方法 mill 和 openNew,先看 mill 这个比较重要的方法
mill & millRun
1 | // mill performs post-rotation compression and removal of stale log files, |
- sync.Once 懒加载,启动清理日志文件的协程
- 通过向 channel 传递信息触发日志文件的清理操作
这里写入 channel 的部分也挺有技巧的,搭配 select + default 来实现并发情况下丢弃后续的写入信息。因为一段时间内 mill 触发多次没有意义,所以做了这样一个处理
接着看 openNew 方法
openNew
1 | // openNew opens a new log file for writing, moving any old log file out of the |
- 文件路径中不存在的文件夹也会顺路全部创建
- 如果文件已经存在,则会先对原文件进行归档操作
- 创建新文件
millRunOnce
1 | // millRunOnce performs compression and removal of stale log files. |
millRunOnce 就是真正执行日志的删除和压缩这些清理操作的地方,主要都是些业务内容了
值得一提的是 oldLogFiles 是通过遍历存储日志的文件夹,匹配文件名来判断一个文件是否属于它来进行管理的,所以可能对应文件夹下文件的命名需要稍微注意
oldLogFiles 中也依据时间对文件进行了排序,所以优先被清理的是旧文件
rotate
1 | // rotate closes the current file, moves it aside with a timestamp in the name, |
最后回头看负责日志分割的 rotate 方法旧比较清晰了,因为用到的 openNew 和 mill 之前已经遇到过了
- 关闭旧文件
- 创建新文件
- 触发文件清理
其他内容
- 可以直接使用 Logger.Rotate 方法来直接强制触发一次日志分割操作,可以凭借这个方法实现一些自定义的日志切割规则
- millCh 肉眼可见的可以优化成
chan struct{},节省一点内存空间,这也是使用 channel 做信息通知时的常用伎俩 - 代码整体不复杂,方法的职责划分做的很好,做到了原子方法,拆分的很细致
注意事项
- 判断是否属于日志文件的方法是匹配文件名,所以日志文件如果重命名就可能导致 lumberjack 不识别和管理
- “ Lumberjack 假设只有一个进程正在写入输出文件。在同一台计算机上的多个进程中使用相同的伐木工人配置将导致不正确的行为。” 根本原因还是在于使用文件名匹配的方式管理日志文件,多进程操作时可能会因为并行执行而引发问题


